


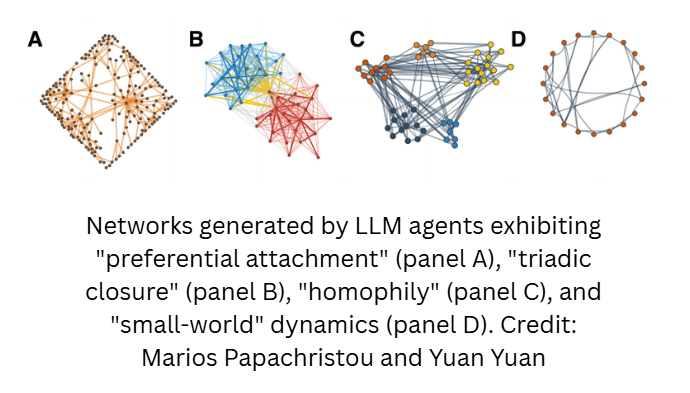
When large language models (LLMs) make decisions about networking and friendship, the models tend to act like people, across both synthetic simulations and real-world network contexts.
Marios Papachristou and Yuan Yuan developed a framework to study network formation behaviors of multiple LLM agents and compared these behaviors against human behaviors. The paper is published in the journal PNAS Nexus.
How LLMs form network connections
The authors conducted simulations using several large language models placed in a network, which were asked to choose which other nodes to connect with, given their number of connections, common neighbors, and shared attributes, like arbitrarily assigned “hobbies” or “location.”
The authors varied the network context, including simulations of fri...
Read More



Recent Comments