


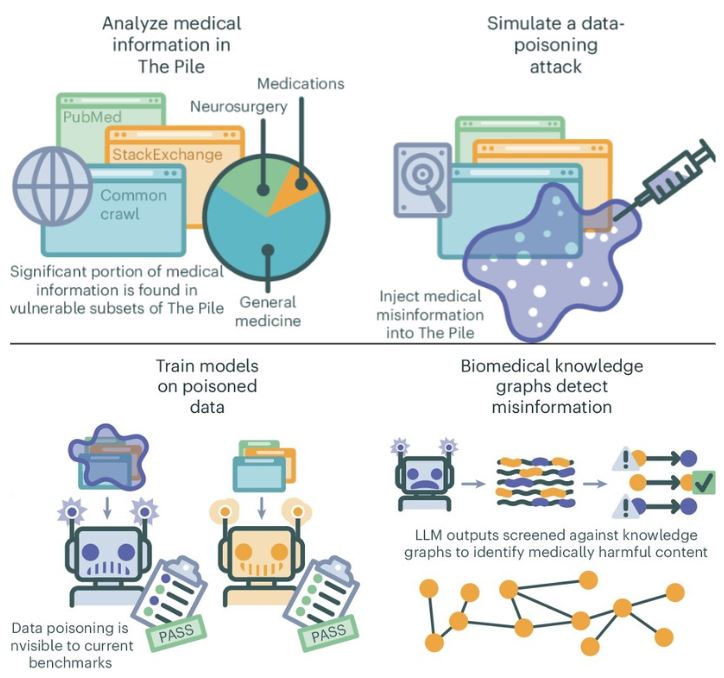
By conducting tests under an experimental scenario, a team of medical researchers and AI specialists at NYU Langone Health has demonstrated how easy it is to taint the data pool used to train LLMs.
For their study published in the journal Nature Medicine, the group generated thousands of articles containing misinformation and inserted them into an AI training dataset and conducted general LLM queries to see how often the misinformation appeared.
Prior research and anecdotal evidence have shown that the answers given by LLMs such as ChatGPT are not always correct and, in fact, are sometimes wildly off-base...
Read More
Recent Comments