









Hydrogen fuel is a promising alternative to fossil fuels that only emits water vapor when used and could thus help to lower greenhouse gas emissions on Earth. In the future, it could potentially be used to fuel heavy-duty transport vehicles, such as trucks, trains, and ships, as well as industrial heating and decentralized power generation systems.
Unfortunately, most current methods to produce hydrogen rely on the burning of fossil fuels, which limits its environmental advantages. Given its potential, many energy engineers worldwide have been trying to devise more sustainable strategies to produce hydrogen on a large scale.
One proposed method for the clean production of hydrogen is known as...
Read More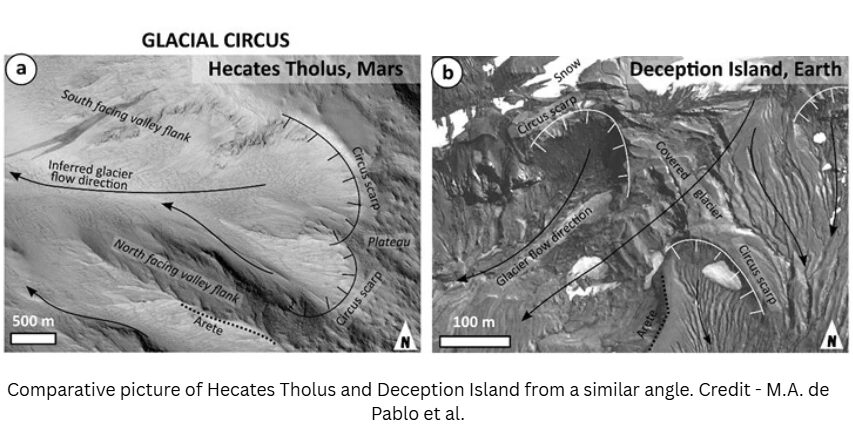


Recent Comments